
Neural Task Planning with And-Or Graph Representations
Paper
Tianshui Chen, Riquan Chen, Lin Nie, Xiaonan Luo, Xiaobai Liu, and Liang Lin .Neural Task Planning with And-Or Graph Representations.IEEE Transactions on Multimedia (TMM), 2018 Paper
Abstract
This paper focuses on semantic task planning, i.e., predicting a sequence of actions toward accomplishing a specific task under a certain scene, which is a new problem in computer vision research. The primary challenges are how to model taskspecific knowledge and how to integrate this knowledge into the learning procedure. In this work, we propose training a recurrent long short-term memory (LSTM) network to address this problem, i.e., taking a scene image (including pre-located objects) and the specified task as input and recurrently predicting action sequences. However, training such a network generally requires large numbers of annotated samples to cover the semantic space (e.g., diverse action decomposition and ordering). To overcome this issue, we introduce a knowledge and-or graph (AOG) for task description, which hierarchically represents a task as atomic actions. With this AOG representation, we can produce many valid samples (i.e., action sequences according to common sense) by training another auxiliary LSTM network with a small set of annotated samples. Furthermore, these generated samples (i.e., task-oriented action sequences) effectively facilitate training of the model for semantic task planning. In our experiments, we create a new dataset that contains diverse daily tasks and extensively evaluate the effectiveness of our approach.
Problem Description
Predicting the sequence of actions toward accomplishing a specific task under a certain scene.
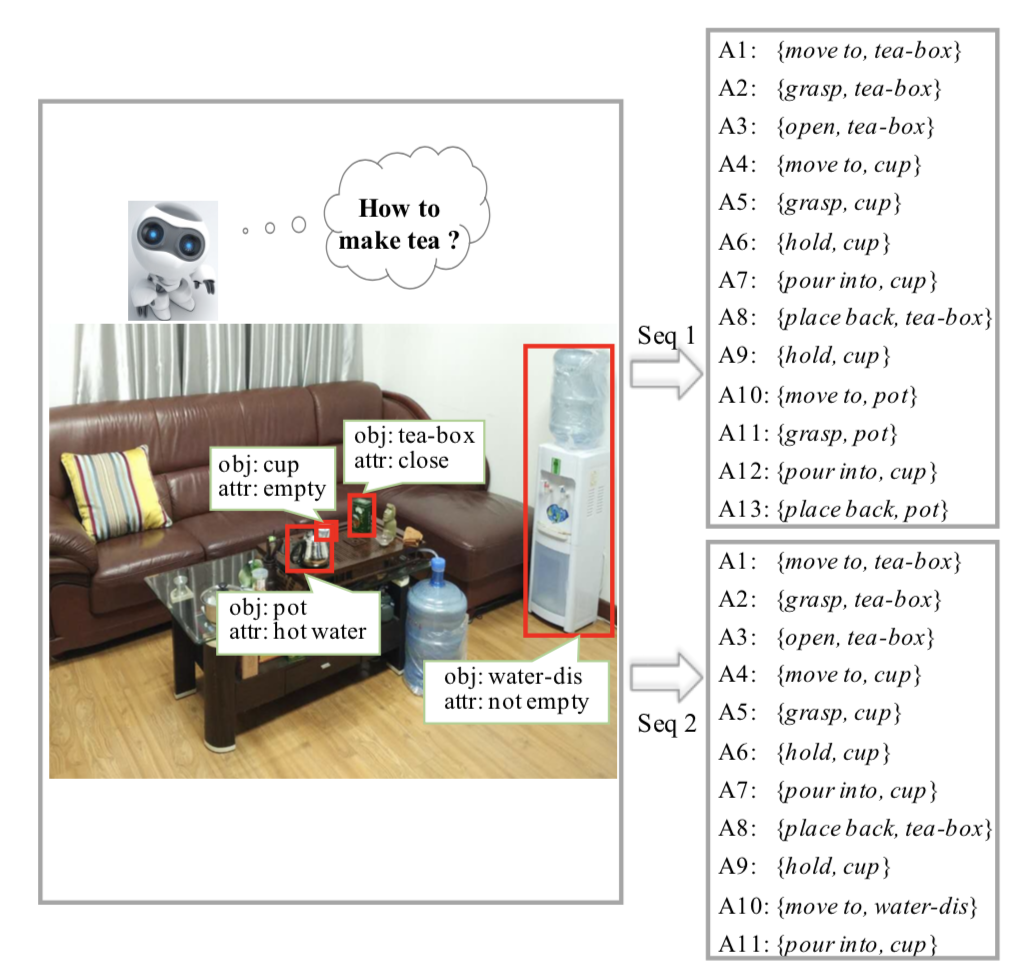
Fig. 1. Two alternative action sequences, inferred according to the joint understanding of the scene image and task semantics, for completing the task “make tea” under a given office scene. An agent can achieve this task by successively executing either of the sequences.
Framework
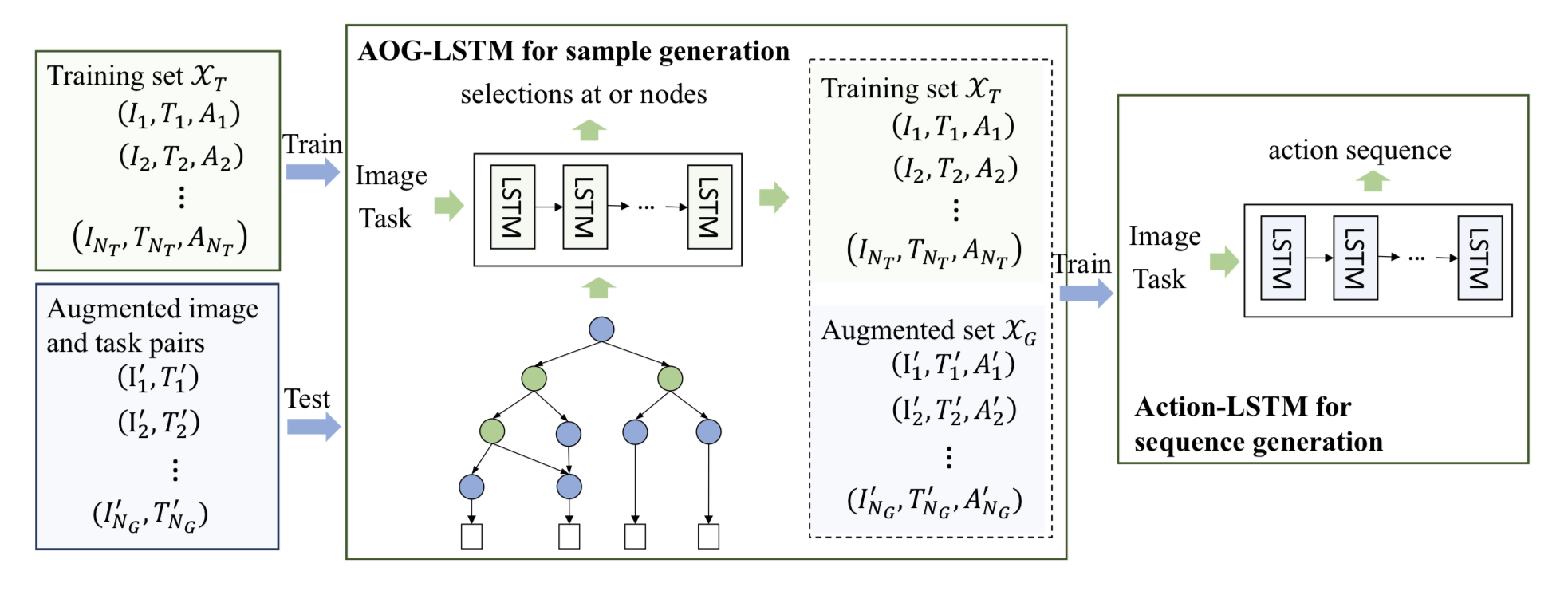
Fig. 2. An overall introduction of the proposed method. The AOG-LSTM network is trained using the samples from the small training set, and it can be used to generate a relatively large augmented set. The augmented set, together with the training set, is used to train the Action-LSTM network, which can directly predict the action sequence to complete a given task under a certain scene.

Fig. 3. An example of a knowledge and-or graph for describing the task “pour a cup of water” shown in (a) and two parsing graphs and their corresponding action sequences under two specific scenes shown in (b).
Experimental Results
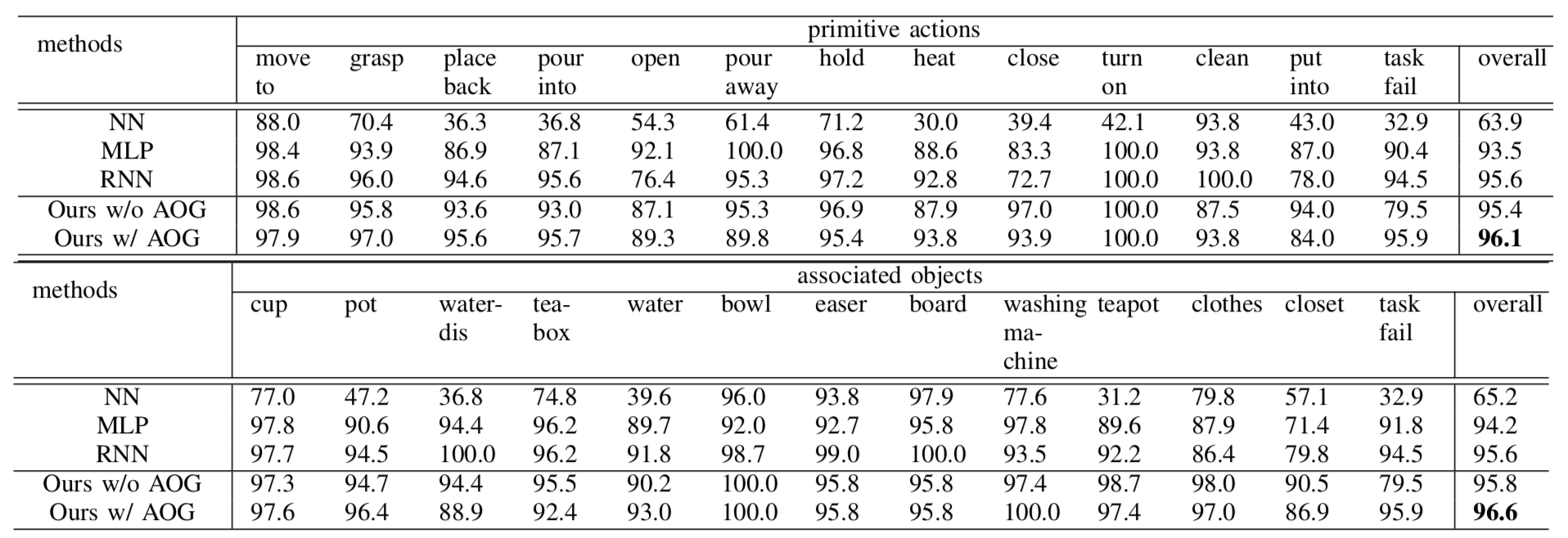
TABLE 1. Accuracy of the primitive actions and associated objects.

TABLE 2. Sequence accuracy.

Fig. 4. Some atomic action sequences regarding given scene images and tasks generated by our method.
REFERENCES
[1] L. Lin, H. Gong, L. Li, and L. Wang, “Semantic event representation and recognition using syntactic attribute graph grammar,” Pattern Recognition Letters, vol. 30, no. 2, pp. 180–186, 2009
[2] J. Sung, B. Selman, and A. Saxena, “Learning sequences of controllers for complex manipulation tasks,” in Proceedings of the International Conference on Machine Learning, 2013.
[3] W. Li, J. Joo, H. Qi, and S.-C. Zhu, “Joint image-text news topic detection and tracking by multimodal topic and-or graph,” IEEE Transactions on Multimedia, vol. 19, no. 2, pp. 367–381, 2017.
