
Fusing Object Context to Detect Functional Area for Cognitive Robots
Paper
Hui Cheng, Junhao Cai, Quande Liu, Zhanpeng Zhang, Kai Yang, Chen Change Loy, Liang Lin, “Fusing Object Context to Detect Functional Area for Cognitive Robots”, Proc. of IEEE Int. Conf. on Robotics and Automation (ICRA) Paper Vedio
Abstract
A cognitive robot usually needs to perform multiple tasks in practice and needs to locate the desired area for each task. Since deep learning has achieved substantial progress in image recognition, to solve this area detection problem, it is straightforward to label a functional area (affordance) image dataset and apply a well-trained deep-model-based classifier on all the potential image regions. However, annotating the functional area is time consuming and the requirement of large amount of training data limits the application scope.We observe that the functional area are usually related to the surrounding object context. In this work, we propose to use the existing object detection dataset and employ the object context as effective prior to improve the performance without additional annotated data. In particular, we formulate a two-stream network that fuses the object-related and functionality-related feature for functional area detection. The whole system is formulated in an end-to-end manner and easy to implement with current object detection framework. Experiments demonstrate that the proposed network outperforms current method by almost 20% in terms of precision and recall.
Framework

Fig 1: An overview of our proposed method. Object context features (extracted from the shaded areas) are employed to facilitate functional area detection indicated by the bounding boxes.
Architecture
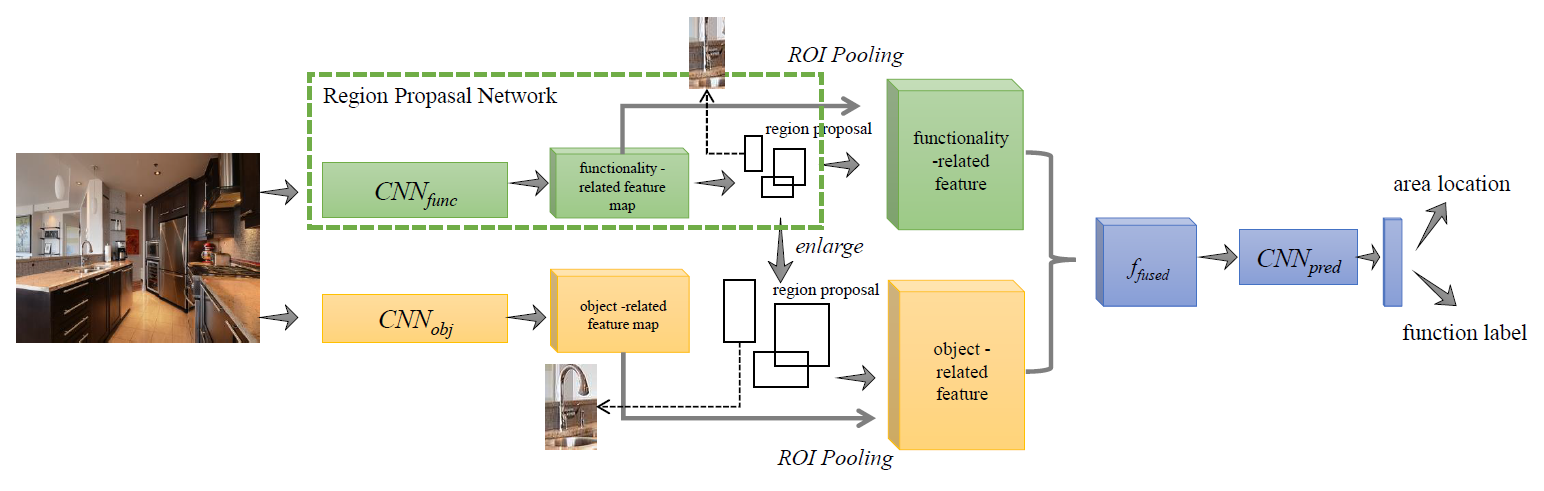
Fig 2: An illustration of the proposed two-stream network. The upper stream (the green part) extracts the functionality-related feature and the lower stream (the yellow part) extracts the object-related feature. Note that the object-related feature is extracted from the enlarged region of the area proposal. In this case, we extract and incorporate the surrounding object information for final area inference.
Experimental results
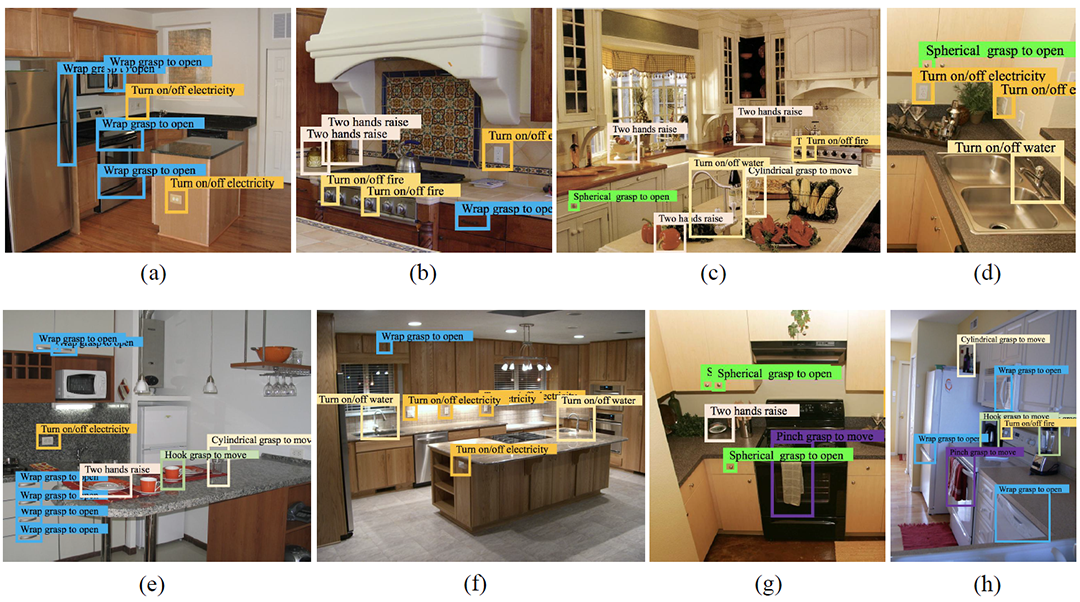
Fig 3: Example results of the proposed method
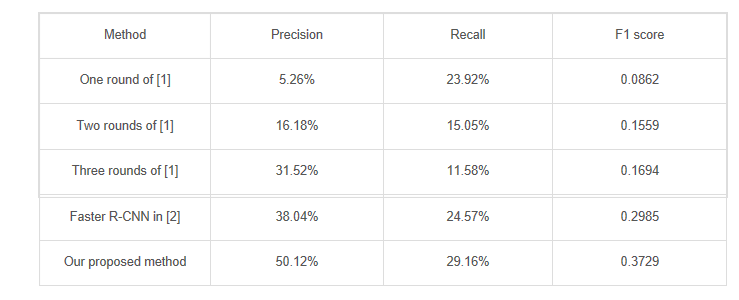
TABLE 1: PRECISION, RECALL AND F1 SCORE OF DIFFERENT METHODS.

Fig 4: Confusion matrix of the result produced by the proposed method. The vertical axis is the ground truth label and the horizontal axis is the predicted label.
REFERENCES
[1] Ye C, Yang Y, Mao R, et al. What can i do around here? deep functional scene understanding for cognitive robots[C]//Robotics and Automation (ICRA), 2017 IEEE International Conference on. IEEE, 2017: 4604-4611.
[2] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015: 91-99.
