
Facial Landmark Localization
Paper
- Lingbo Liu, Guanbin Li*, Yuan Xie, Yizhou Yu, Qing Wang and Liang Lin, “Facial Landmark Machines: A Backbone-Branches Architecture with Progressive Representation Learning.”, To appear in IEEE Transactions on Mulitmedia (TMM) Dataset
Introduction
Facial landmark localization plays a critical role in face recognition and analysis. In this paper, we propose a novel cascaded Backbone-Branches Fully Convolutional Neural Network~(BB-FCN) for rapidly and accurately localizing facial landmarks in unconstrained and cluttered settings. Our proposed BB-FCN generates facial landmark response maps directly from raw images without any pre-processing. It follows a coarse-to-fine cascaded pipeline, which consists of a backbone network for roughly detecting the locations of all facial landmarks and one branch network for each type of detected landmarks for further refining their locations. Extensive experimental evaluations demonstrate that our proposed BB-FCN can significantly outperform the state of the art under both constrained (i.e. within detected facial regions only) and unconstrained settings. We further confirm that high-quality facial landmarks localized with our proposed network can also improve the precision and recall of face detection.
Architecture
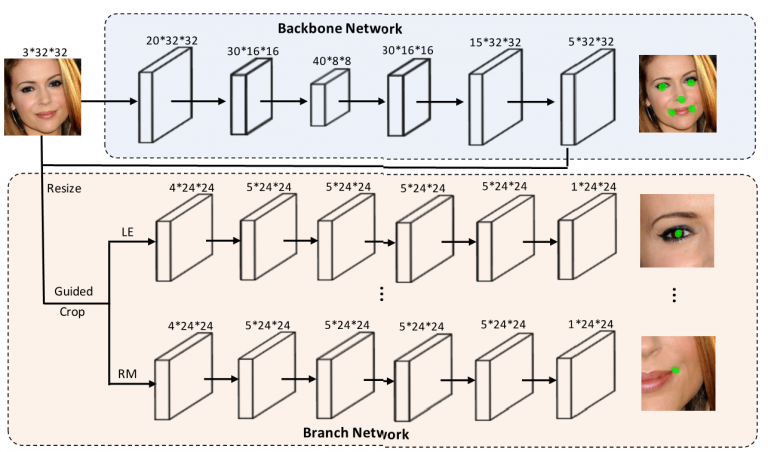
Fig.1: The architecture of the proposed Backbone-Branches Fully Convolutional Neural Network. It is capable of producing pixel-wise facial landmark response maps in a progressive way. The backbone network first generates low resolution response maps identifying rough landmark locations via a fully convolutional network. The branch networks then produce fine response maps over local regions for more accurate landmark localization. There are five branches corresponding to five types of facial landmarks, and each branch refines the response map for one type of landmarks. Only down-sampling, up-sampling, and prediction layers are shown and intermediate convolutional layers are omitted in the network branches.
Performance Evaluation for Unconstrained Settings

Fig. 2: Qualitative facial landmark detection results on ALW in unconstrained settings. Our BB-FCN is capable of dealing with unconstrained facial images, even though the location of facial regions and the number of faces in the image are unknown.
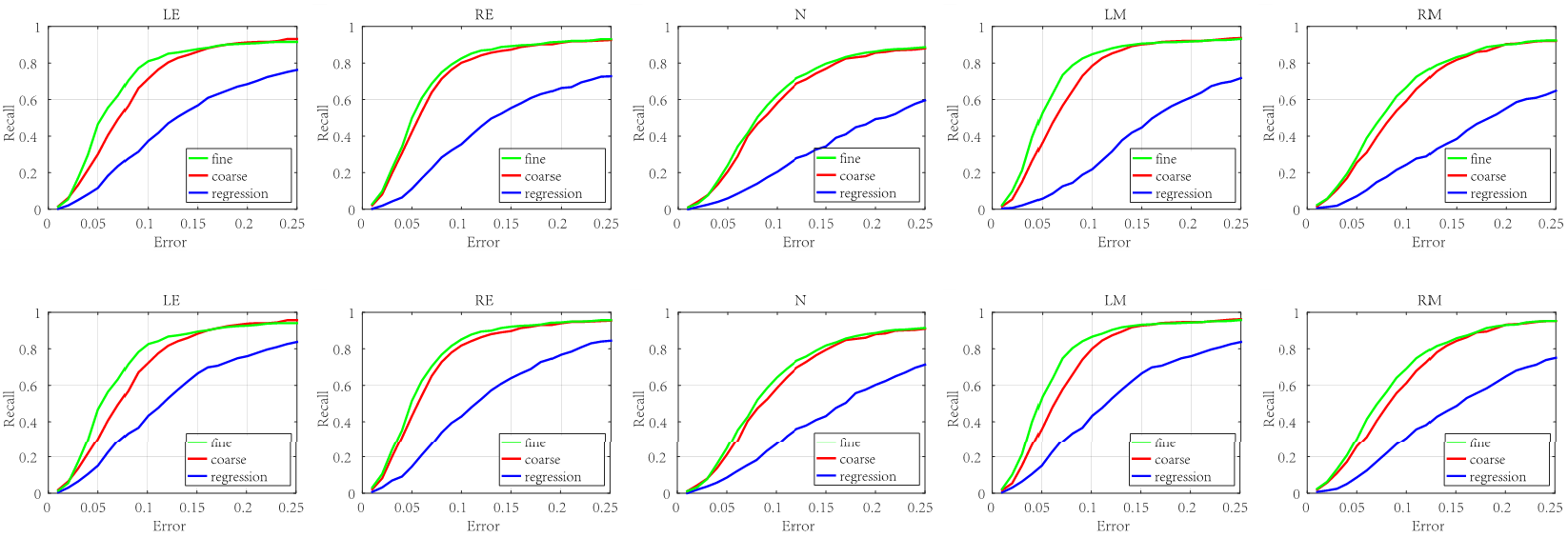
Fig. 3: The recall of landmarks on AFW in unconstrained settings. The curves labeled fine and coarse represent the performance of models with and without branch networks, respectively. The curve labeled regression represents the performance of the regression network based on a single fully convolutional network. The top five figures are the recall when only with 15 predictive landmarks per image. The bottom five figures are the results with 30 predictive landmarks.
Comparison with the State of the Art
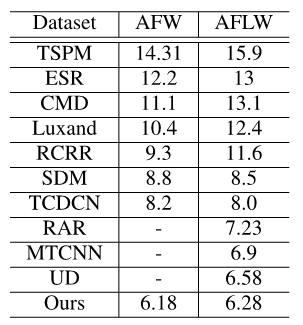
Table 1: Average mean errors of our method and all other competing methods on AFW and AFLW.
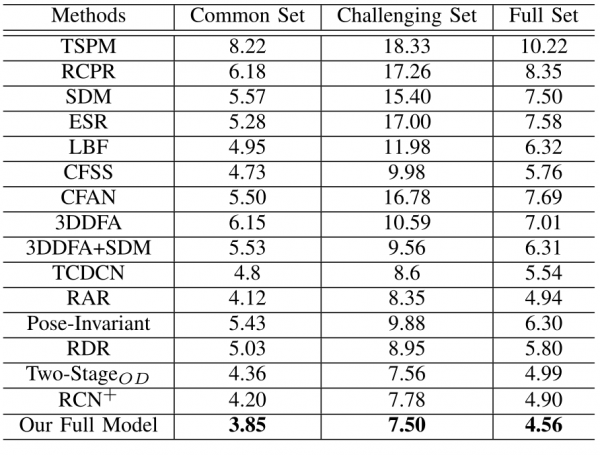
Table 2: Average mean errors of our method and all other competing methods on 300W.

Fig. 4: Qualitative facial landmark localization results by our method. The top two rows show results on AFW, the next two rows show results on AFLW,and the bottom row shows results on LFPW. Our method is robust under occlusion, exaggerated expressions and extreme illumination.
Ablation Study
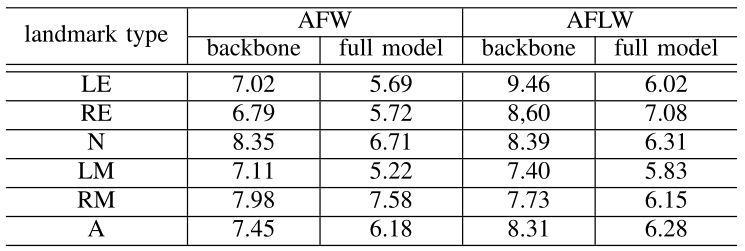
Table 3: Performance evaluation of the complete backbone-branches network and the backbone network alone on AFW and AFLW.
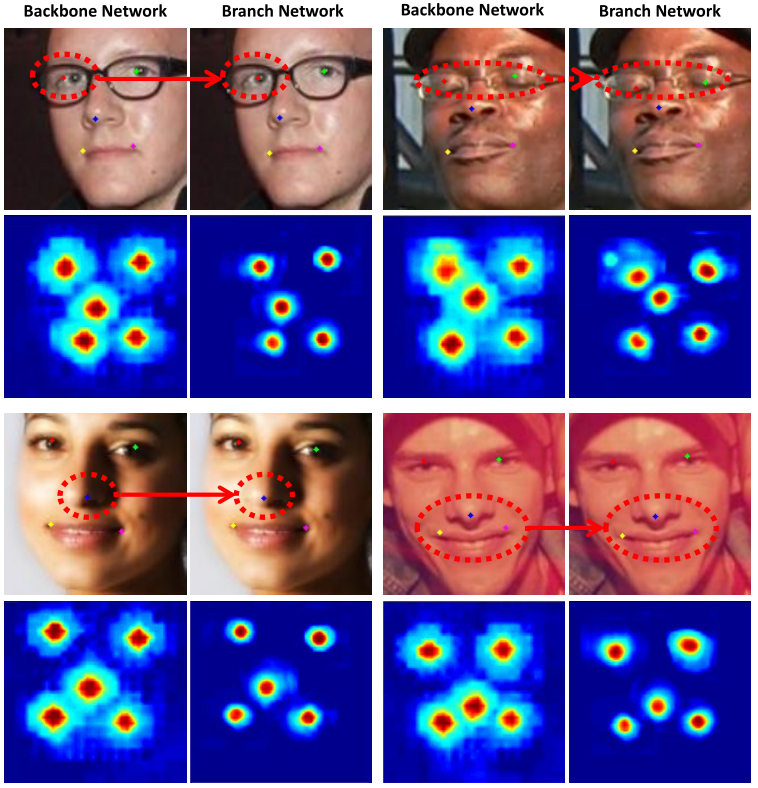
Fig. 5: Examples of improvements made by the branch networks. The response heat maps of the branch networks are more compact and precise.
Evaluation on Face Detection Performance
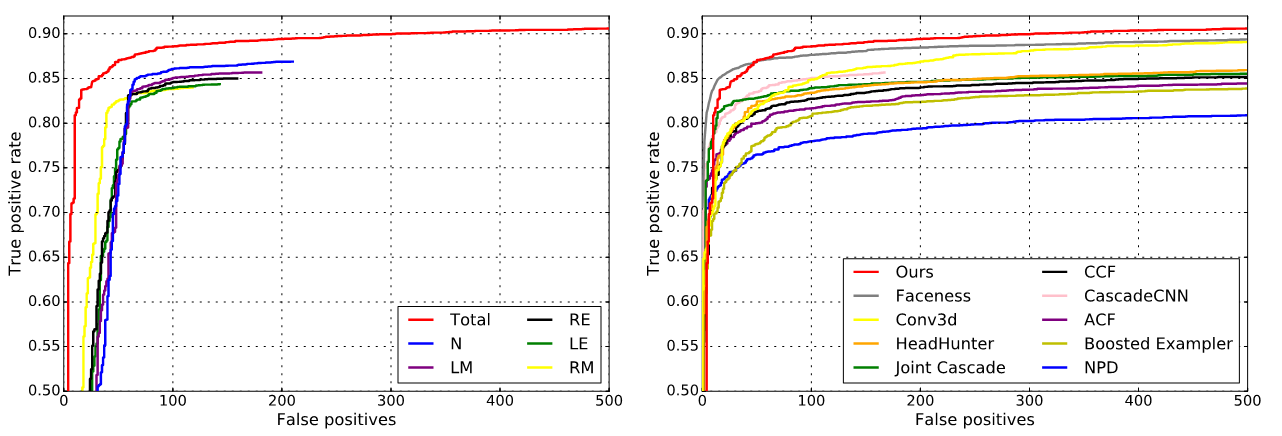
Fig. 6: Left: Face proposals induced by different landmark types exhibit different levels of effectiveness in face detection. Using face proposals induced by all five landmark types significantly improves the performance achieved with individual landmark types. Right: On the FDDB dataset, we compare our method against other state-of-the-art methods. When the number of false positives is fixed at 350, the recall achieved with our method is 90.17%, higher than all other methods.

Fig. 7: Qualitative face detection results. Our method achieves an impressive performance even under severe occlusion and large pose variation.
