
A New Benchmark for Human Parsing
Paper
- “Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing”, Ke Gong, Xiaodan Liang, Dongyu Zhang, Xiaohui Shen, Liang Lin, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. Paper Code Dataset
Introduction
In this paper, we propose a new large-scale benchmark and an evaluation server to advance the human parsing research, in which 50,462 images with pixel-wise annotations on 19 semantic part labels are provided. By experimenting on our benchmark, we present the detailed analyses about the existing human parsing approaches to gain some insights into the success and failures of these approaches. Moreover, we propose a novel self-supervised structure-sensitive learning framework for human parsing, which is capable of explicitly enforcing the consistency between the parsing results and the human joint structures. Our proposed framework significantly surpasses the previous methods on both the existing PASCAL-Person-Part dataset and our new LIP dataset.
Dataset

Figure 1: Annotation examples for our “Look into Person (LIP)” dataset and existing datasets. (a) The images in ATR dataset which are fixed in size and only contain stand-up person instances in the outdoors. (b) The images in the PASCAL-Person-Part dataset which also have lower scalability and only contain 6 coarse labels. (c) The images in our LIP dataset with high appearance variability and complexity.
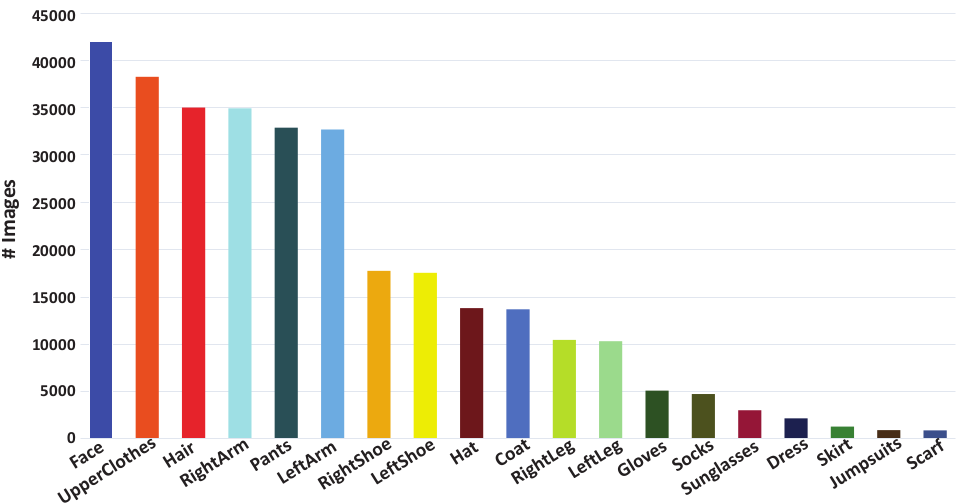
Figure 2: The data distribution on 19 semantic part labels in the LIP dataset.
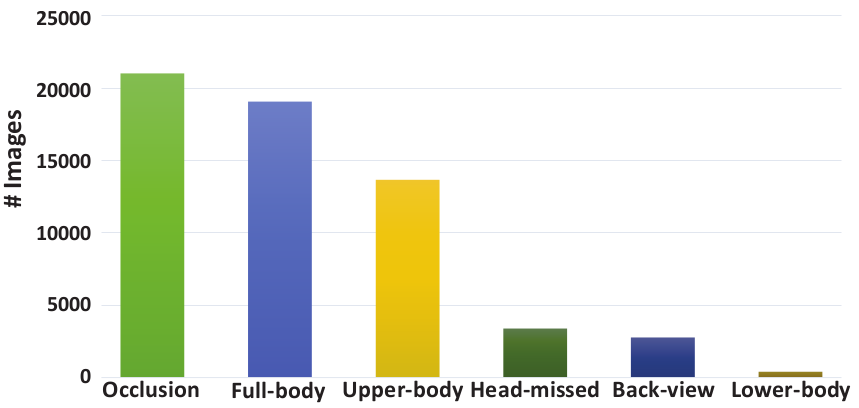
Figure 3: The numbers of images that show diverse visibilities in the LIP dataset, including occlusion, full-body, upper-body, lower-body, head-missed and back-view.
Architecture
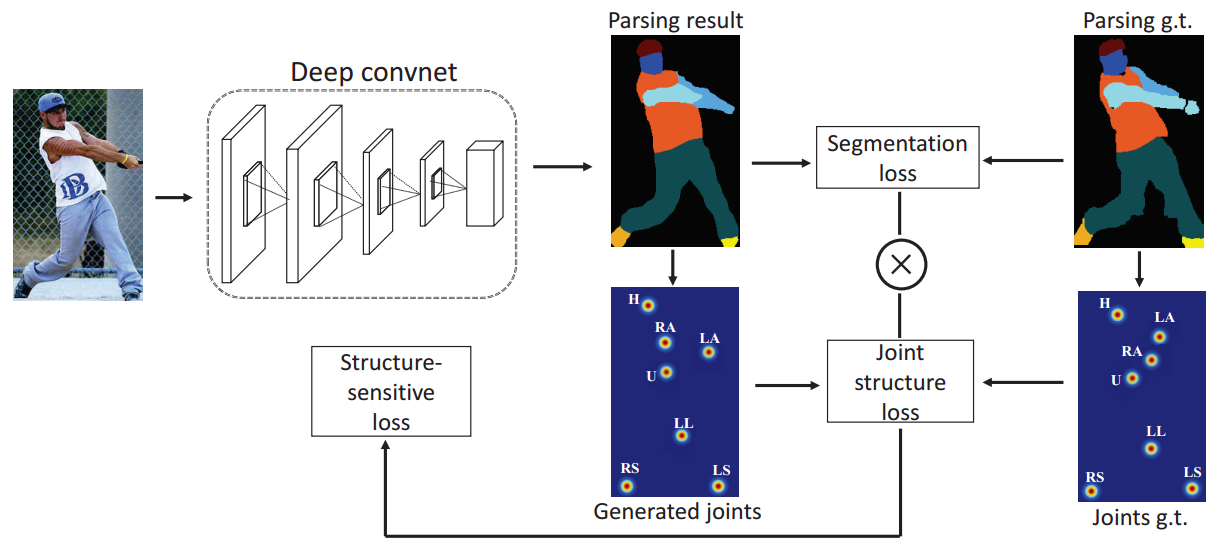
Figure 4: Illustration of our Self-supervised Structure-sensitive Learning for human parsing. An input image goes through parsing networks including several convolutional layers to generate the parsing results. The generated joints and joints ground truth represented as heatmaps are obtained by computing the center points of corresponding regions in parsing maps, including head (H), upper body (U), lower body (L), right arm (RA), left arm (LA), right leg (RL), left leg (LL), right shoe (RS), left shoe (LS). The structure-sensitive loss is generated by weighting segmentation loss with joint structure loss. For clear observation, here we combine nine heatmaps into one map.
Experiments
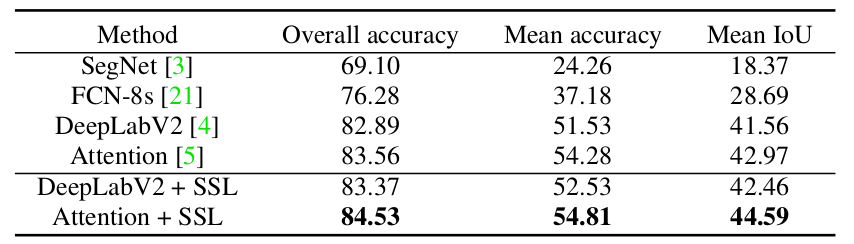
Table 1: Comparison of human parsing performance with four state-of-the-art methods on the LIP test set.
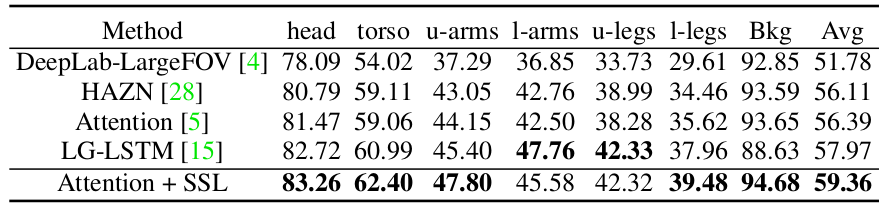
Table 2: Comparison of person part segmentation performance with four state-of-the-art methods on the PASCALPerson-Part dataset

Figure 5: Visualized comparison of human parsing results on the LIP validation set. (a): The upper-body images. (b): The back-view images. (c): The head-missed images. (d): The images with occlusion. (e): The full-body images.
References
[1] X. Liang, C. Xu, X. Shen, J. Yang, S. Liu, J. Tang, L. Lin, and S. Yan. Human parsing with contextualized convolutional neural network. In ICCV, 2015.
[2] X. Chen, R. Mottaghi, X. Liu, S. Fidler, R. Urtasun, et al. Detect what you can: Detecting and representing objects using holistic models and body parts. In CVPR, 2014.
[3] L.-C. Chen, Y. Yang, J. Wang, W. Xu, and A. L. Yuille. Attention to scale: Scale-aware semantic image segmentation. In CVPR, 2016.
