
Deep Human Action Understanding from Still Images
发布人:吕梅
发布日期:2019-06-26
Paper
- Zhujin Liang, Xiaolong Wang, Rui Huang, Liang Lin. An Expressive Deep Model for Parsing Human Action from a Single Image. Proc. of IEEE International Conference on Multimedia and Expo (ICME), 2014. (oral presentation, Best Student Paper Award) PDF
KEY POINTS
- Recognizing human actions from still images;
- An expressive deep model to integrate human layout and surrounding contexts;
- To bridge the semantic gap, we applied manually labeled data (human poses and objects) for deep learning;
- Our framework is robust to sometimes unreliable inputs, and outperforms the state-of-the-art methods.
Application
-
Query Answering
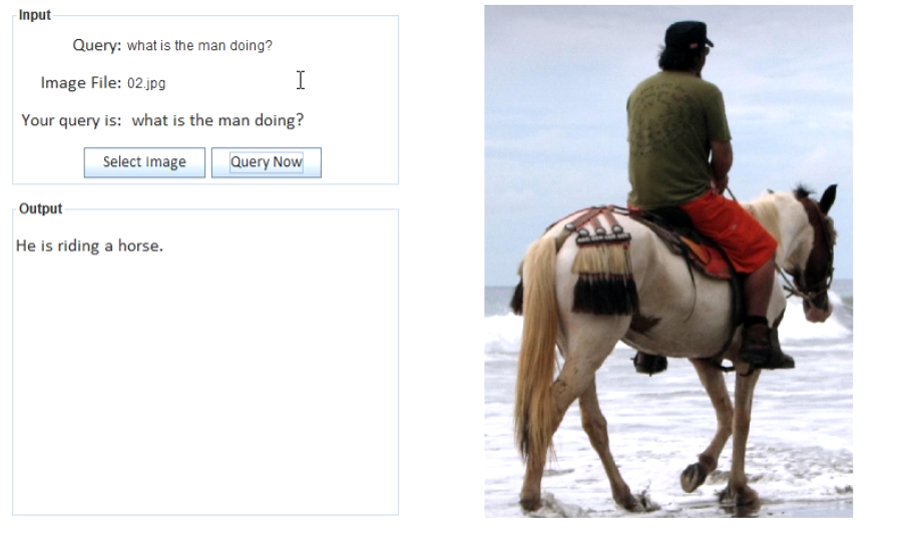
-
Image Retrieval
Searching image with action description.
Searching similar image.

Challenges
- In lack of temporal motion information;
- Large human variations in poses and appearances;
- Difficulty in integrating the information of human poses, surrounding objects and scene contexts.
Framework

Body Part Estimation
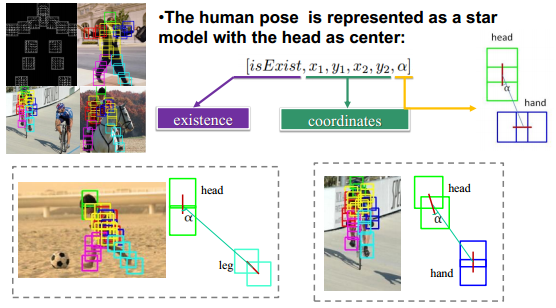
Person-Object Interation
We apply trained DPMs to detect 5 types of objects (i.e., “bike”, “camera”, “computer”, “horse”, “instrument”).

Extracting Scene Global Feature
We apply the linear SPM based on sparse coding to classify the action categories of an given image as a whole.
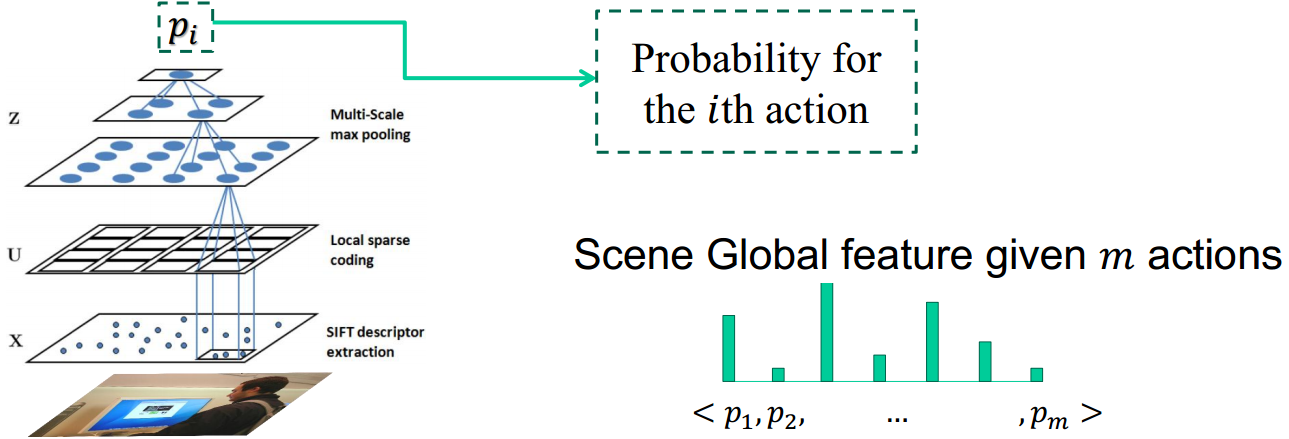
DBN Model
During learning:
- We applied RBM pre-training and fine tuning;
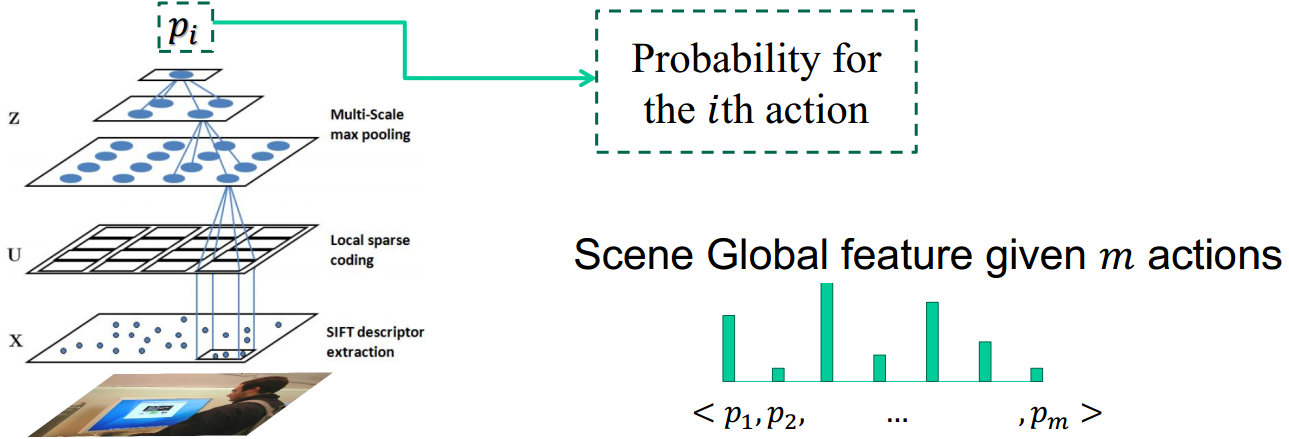
- We used manually labeled data(human part and object locations)

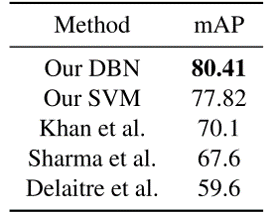
Experiment Results in Willow Actions Dataset
Here is the link for the Willow Actions Dataset: http://www.di.ens.fr/willow/research/stillactions/
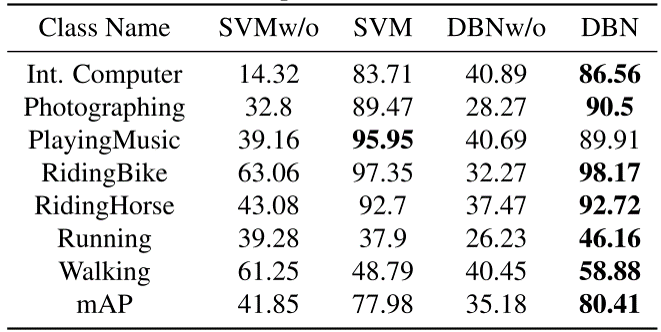
- We first examine our method without considering the global scene features:
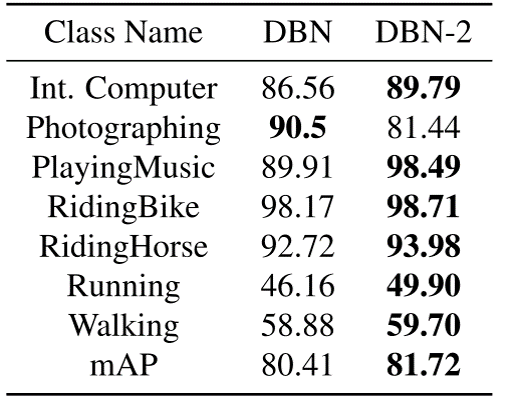
- We then add the global scene feature as inputs, we name this approach as DBN-2:
- Sample results of parsing actions from still images using our framework.

References
- Y. Yang and D. Ramanan. Articulated Pose Estimation with Flexible Mixtures of Parts. In CVPR, 2011.
- P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan, “Object detection with discriminatively trained part based models,” In TPAMI, vol. 32, no. 9, pp. 1627–1645, 2010.
- J. Yang, K. Yu, Y. Gong, and T. Huang. Linear spatial pyramid matching uisng sparse coding for image classification. In CVPR, 2009.
